Natural Language Processing an大數(shù)據(jù)技術(shù)與應(yīng)用
知識圖譜
應(yīng)用場景:
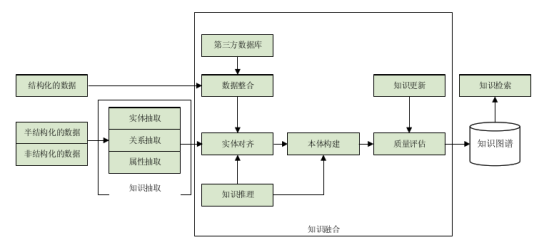
可從書籍、檔案等非結(jié)構(gòu)化數(shù)據(jù)及知識庫、數(shù)據(jù)庫等結(jié)構(gòu)化數(shù)據(jù)源中進(jìn)行自動知識抽取、知識標(biāo)引、知識加工,并構(gòu)建相關(guān)的知識圖譜?;谥R圖譜實(shí)現(xiàn)知識的檢索、集結(jié)、推理與可視化。實(shí)現(xiàn)從文本數(shù)據(jù)到知識網(wǎng)絡(luò)的加工轉(zhuǎn)化,深度挖掘數(shù)據(jù)價值。
案例:
中國文史出版社資源加工及產(chǎn)品制作工具建設(shè)項目
地方志數(shù)字化與知識抽取課題(文化部立項,科技部驗收)
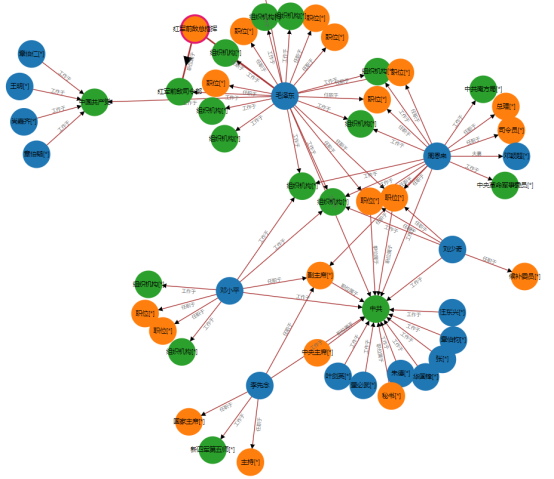
示例:
體系架構(gòu)